この記事は運営堂様のメールマガジン(毎日堂)で紹介されました!
とうとう旧版のSearch Consoleで「Fetch as Google」が利用できなくなりました。
検索アナリティクスにはじまり、サイトへのリンクやインデックスステータスなど多くの機能が廃止されており、いよいよ新しいSearch Consoleへの切替えが最終フェーズに入ろうとしています。
新しいSearch Consoleの使い方にはもう慣れましたか?見た目だけでなく項目の場所や繋がり方等、全面刷新されているのでとっつきにくい部分もあるかもしれません。
とりあえず旧版でよく使っていた項目だけでもおさえておきたいところです。そこで今回はFetch as Googleの行い方をおさらいします。
目次
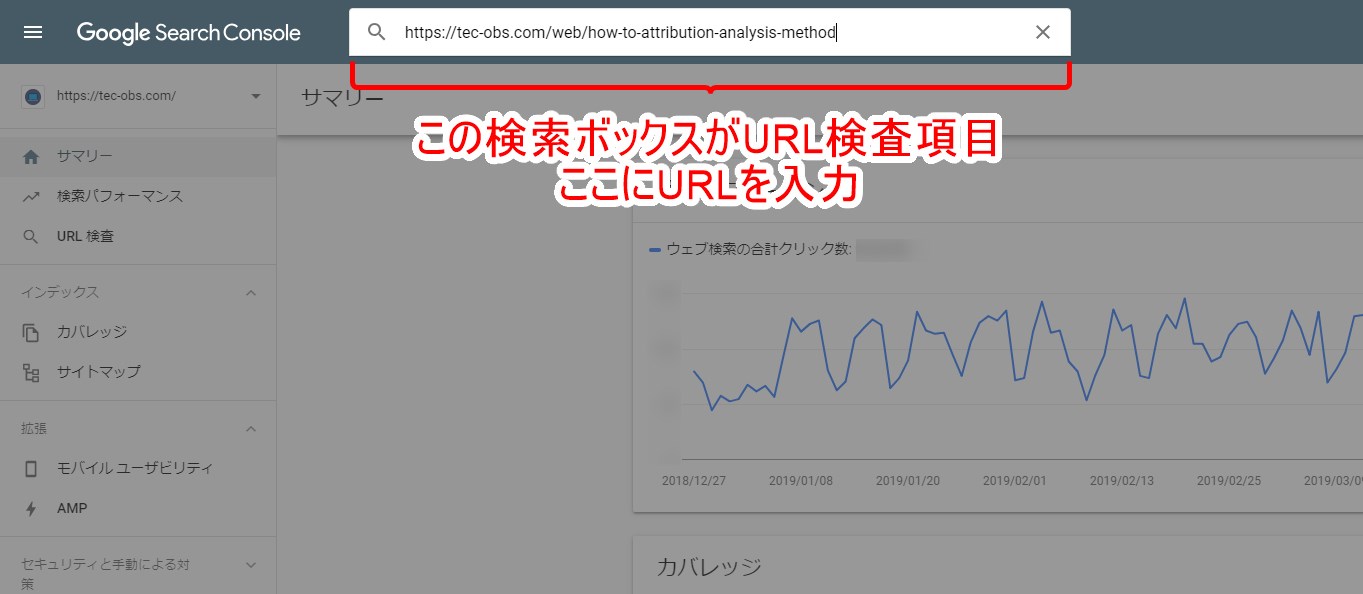
新SearchConsoleの上部に存在する検索ボックスが「URL検査」の項目です。
左カラムにも「URL検査」項目はありますが、クリックするとこの検索ボックスがハイライトされます。
ここに、検査したいURLを入力してEnterを押します。
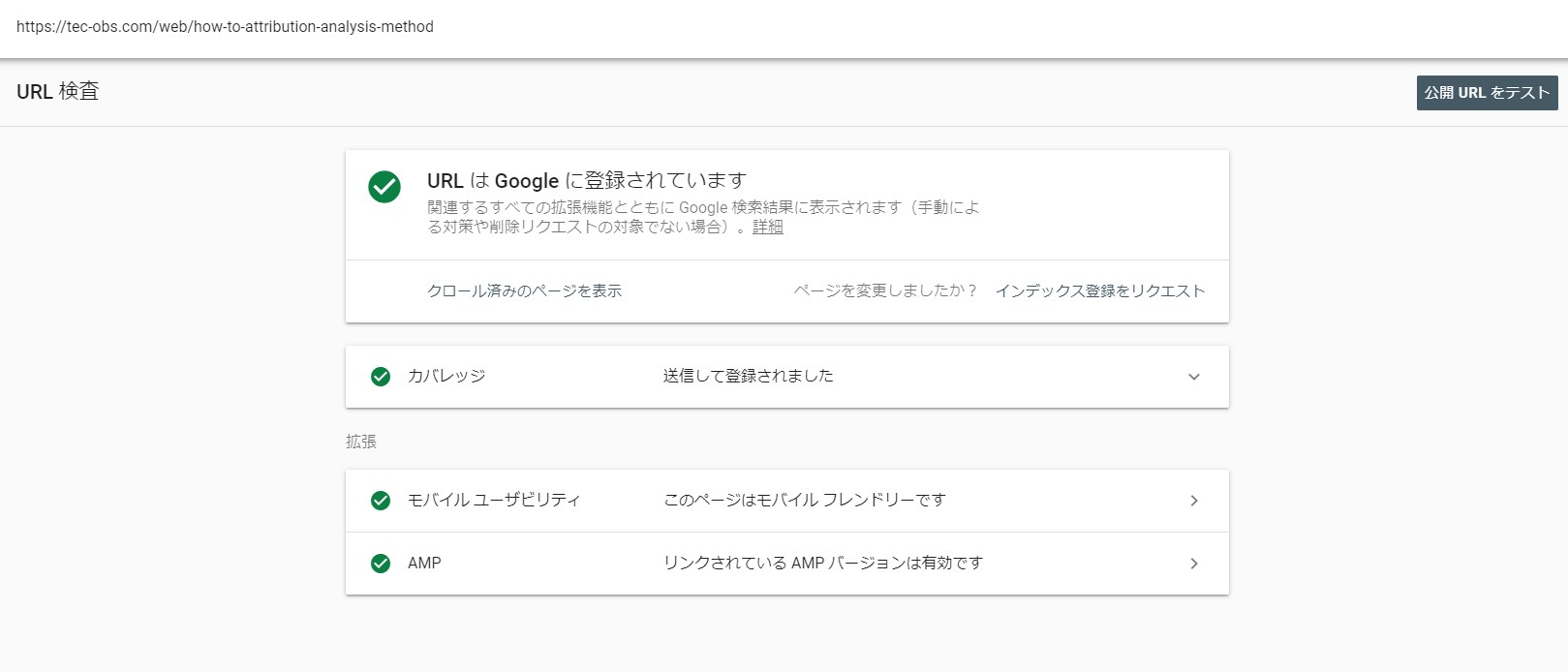
検査が終わると結果が表示されます。
この結果のステータスも旧版と表現が違っているため、慣れるまでは戸惑うこともあるかもしれません。
そこで一旦、他の項目には目をくれず、Fetch as Googleを行うことだけ考えます。
今開いているURL検査結果画面の右上のほうに、濃い色に白文字で「公開URLをテスト」って書かれたボタンがあるはずです。
それを押します。
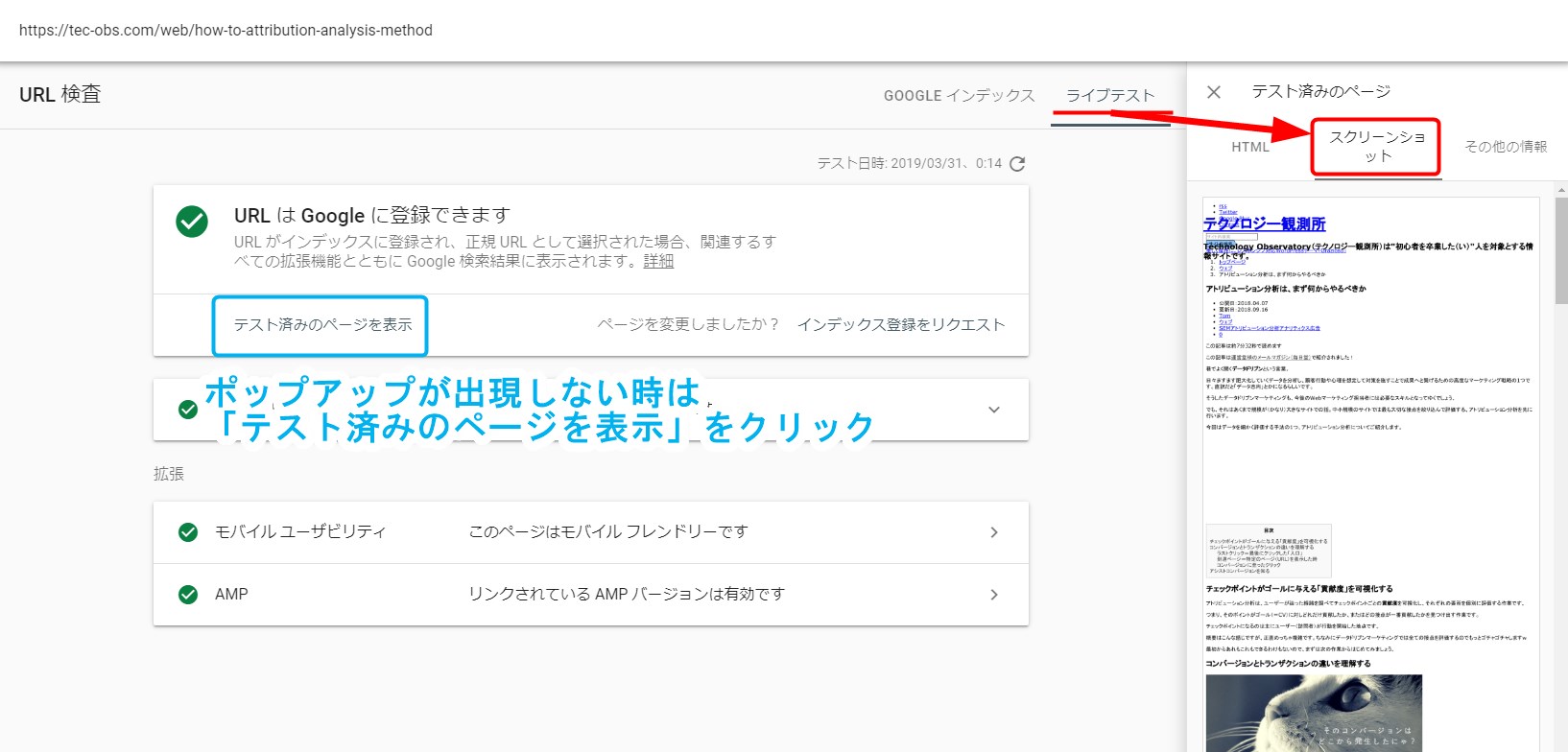
すると画面の右上に「ライブテスト」という項目が追加され、さらに右サイドからページがスライドしてきます。
上に3つタブが並んでおり、その中に「スクリーンショット」があります。
ここがFetch as Googleでいう「取得してレンダリング」を行った際に取得できる、検索エンジンクローラーに見えているページの情報です。
かなり崩れていますね……どうやらこの前のRobots.txt対策が不完全だったようです。
Robots.txt対策についてはこちらをどうぞ↓
旧版のFetch as Googleではインデックス登録をリクエストすることが多かったかと思いますので、その方法をご紹介します。
といっても目立つ位置にあるんですけどね。
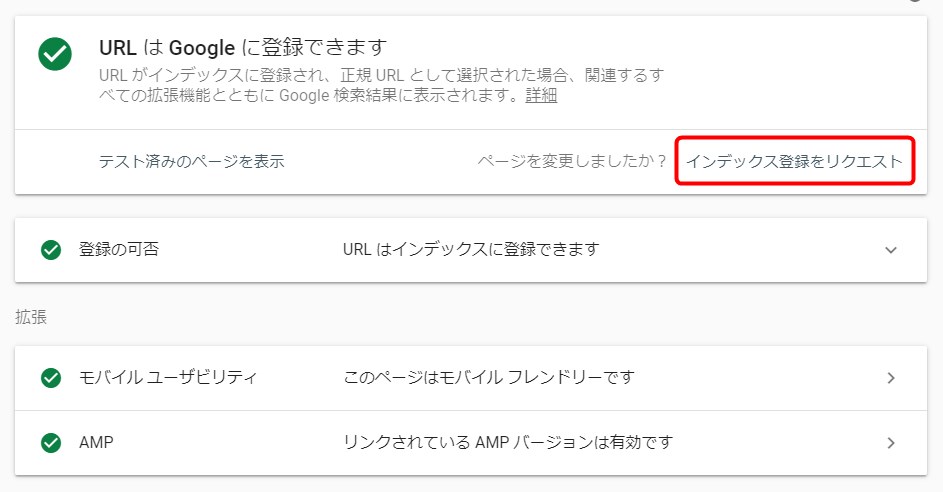
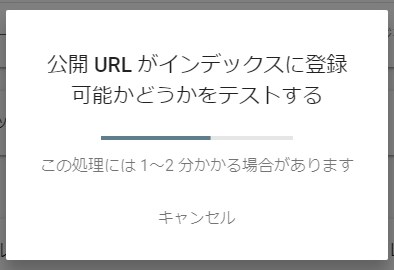
URL検査結果画面の「インデックス登録をリクエスト」を押すだけです。
するとこのようなポップアップが表示されます。
インデックスに登録する条件を満たしているのかを簡易的にチェックしているのだと思います。けっこうかかります。
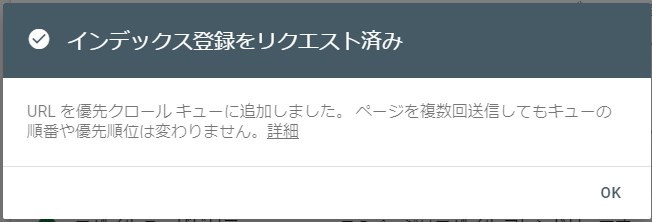
うまくいくとこのように表示されます。
テキストから察するに、どちらかというとインデックス登録ではなく(そのための準備としての)クローリングリクエストだと思うんですけどねぇ…。
「既にURLが発見されているんだからクロールは済んでいる」と考えるかもしれませんが、最後のクロール時から今回のインデックス登録リクエスト時までにタイムラグがある場合、ページの内容が変わっている可能性があるため、再クロールされる確率は高いと思いますし。
リクエストに関してはここまで。もう1つ、Fetch as Googleではページが正常に認識されたかを確認することもできましたよね。その方法をご紹介します。
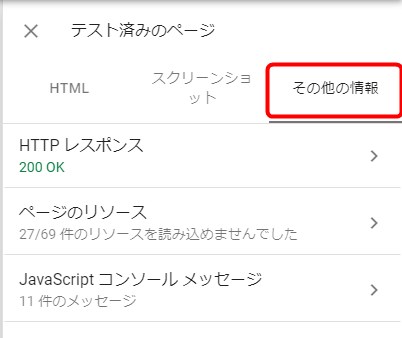
先程行った「URL検査」の「ライブテスト(テスト済みのページを表示)」でスライドインした領域に「その他の情報」というタブがあります。
ここをクリックすると、HTTPレスポンスコードや取得できなかったリソースなどを確認できます。
ちなみに現時点(2019年3月末)では「Robots.txtテスター」はまだ旧版のほうに残っているため、ここで発見したリソースがRobots.txtでブロックされているかをテストするためには一端旧版に移動しなければならないんですよね…。
と、思うじゃん?
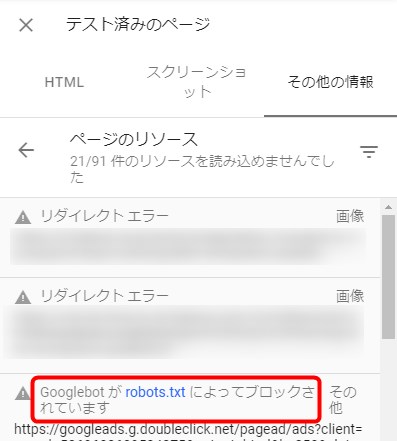
「ページのリソース」部分をクリックして、どのリソースが引っかかったかを見てみます。
するとこの通り、Robots.txtによってブロックされている場合、それが表示されるようになっています。
これは地味に便利。いちいちURLを個別にテストする必要がなくなるかも?
という感じで、旧Search ConsoleのFetch as Googleは新Search Consoleでもだいたい似たようなことが行えるようになっています。
大きな違いとしては、「スクリーンショット」項目に表示されるキャプチャでしょうか。
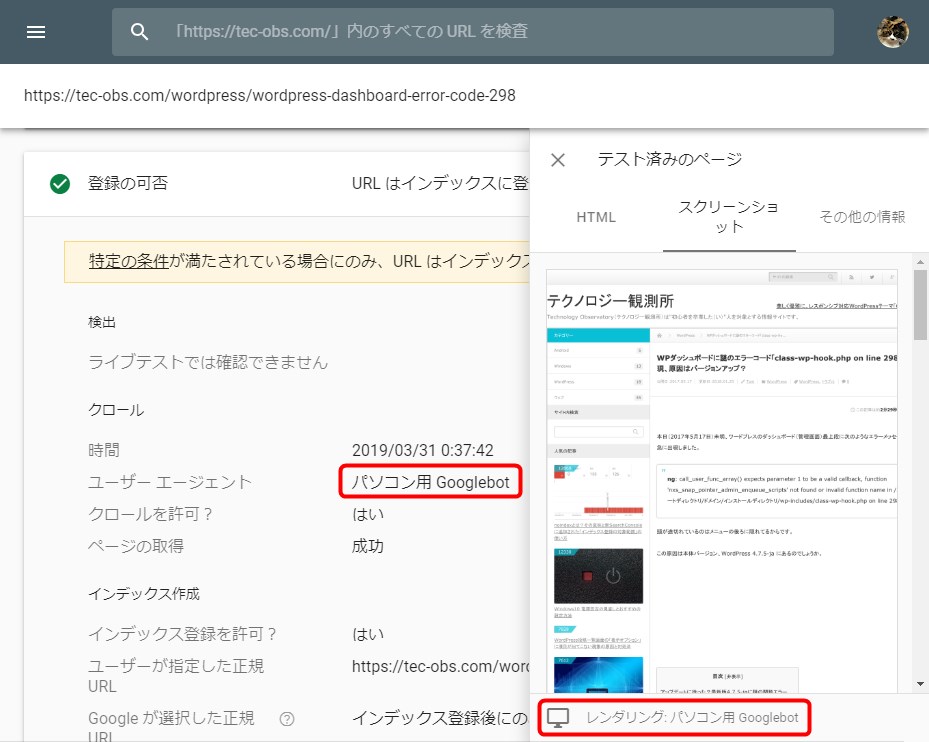
そもそも「URL検査」で表示されるカバレッジ情報は、直近で訪問したクローラーが認識したステータスのみが反映されています。
何がいいたいのかというと、スクリーンショットに表示されるレンダリング画像は対象のページを直近で訪問したクローラーのユーザーエージェントに左右されます。
訪問したのがパソコン版のGooglebot(クローラー)ならパソコン版のレンダリング画像が、スマートフォン(モバイル)版のGooglebotならスマートフォン版のレンダリング画像が表示されます。
旧版ではそもそもFetch as Googleの実行時にPC版/SP版を選べたのですが、URL検査ではその項目はありません。
このため特に、PC版/SP版どちらのGooglebotも訪問できるURL、つまりPCとSPでURLが変化しない(故に正規化を行っていない=canonical/alternateを指定していない)レスポンシブやダイナミックサービング(URLで分けるのではなくユーザーエージェントやビューポートで分けるタイプ)でページを構築している場合は多少注意が必要になります。
あくまでも「直近で」訪問したのがパソコン版Googlebotだった、というだけで、その前に訪問したのはモバイル版Googlebotかもしれませんからね。このへん仕事でもたまに質問されることがあります。
どうしてもモバイル版のレンダリング画像が見たいという場合は「モバイルフレンドリーテスト」を利用すると良いでしょう。
というわけで、新Search ConsoleでFetch as Googleを行う方法でした。
あわせてどうぞ↓
最終変更時間: 2024年4月5日 11:56 AM
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}