くそっやられた…!
というかなんで今まで気が付かなかったんだ!!
Pagespeed InsightsやLighthouseなど、ウェブページのパフォーマンスを数値化してくれるツールを愛用している方は少なくないと思います。
僕もそうです。でも、Search Consoleやモバイルフレンドリーテストで何度やってもレンダリング結果が崩れて表示されていることはありませんか?
仕事で携わったものも含め、正直かなりの確率で遭遇する気がします。
この原因はRobots.txtです。全部じゃないかもしれませんがほとんどの場合はそうだと思います。WordPressでもそうでした。
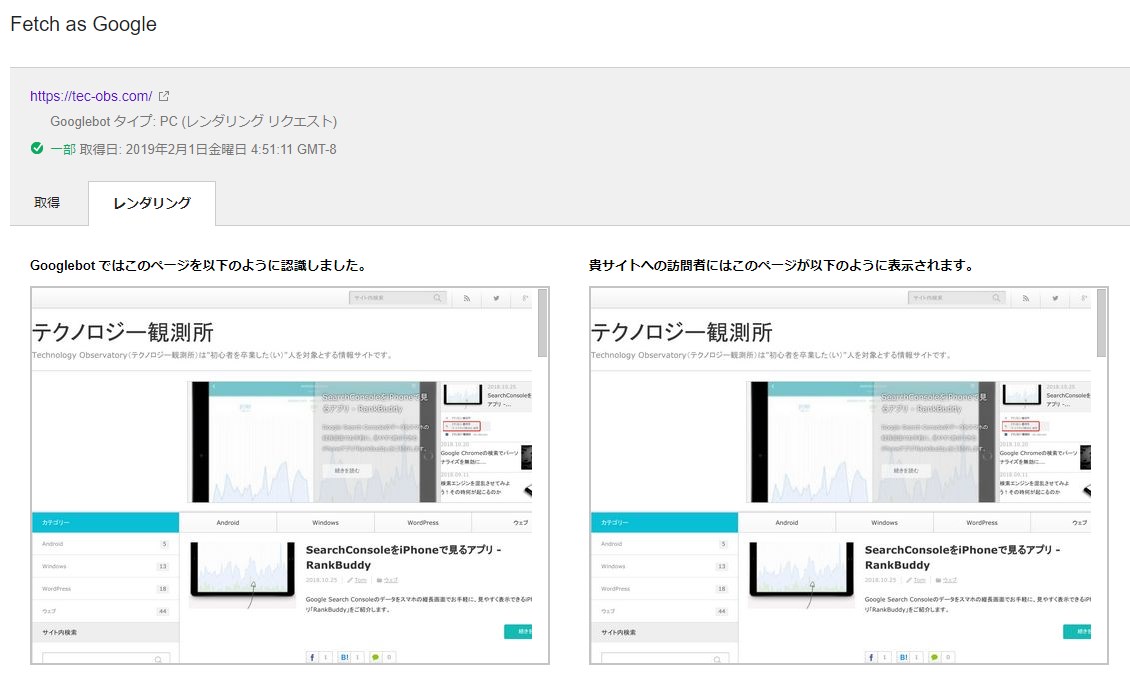
Fetch as Googleでレンダリング結果が崩れて表示されるサイトは要確認

確認方法は、旧Search ConsoleのFetch as Googleで、いくつかのページを取得してレンダリングします。
トップページと下層ページで使用するJSが異なるなど、サイトの形態によってチェック箇所を選ぶ必要があります。
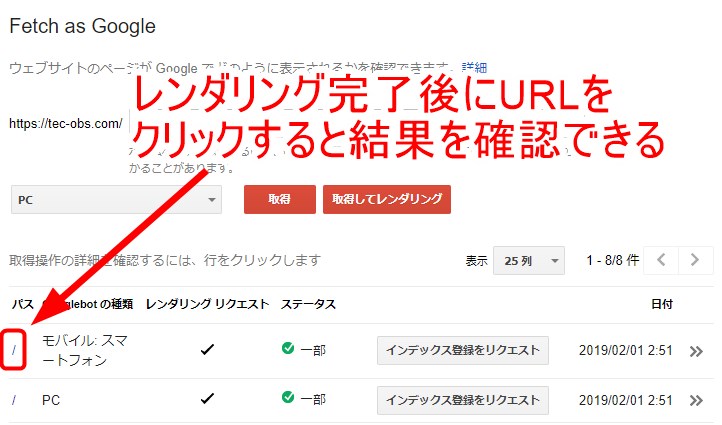
レンダリングが完了したらURL部分をクリックすると結果を確認できます。
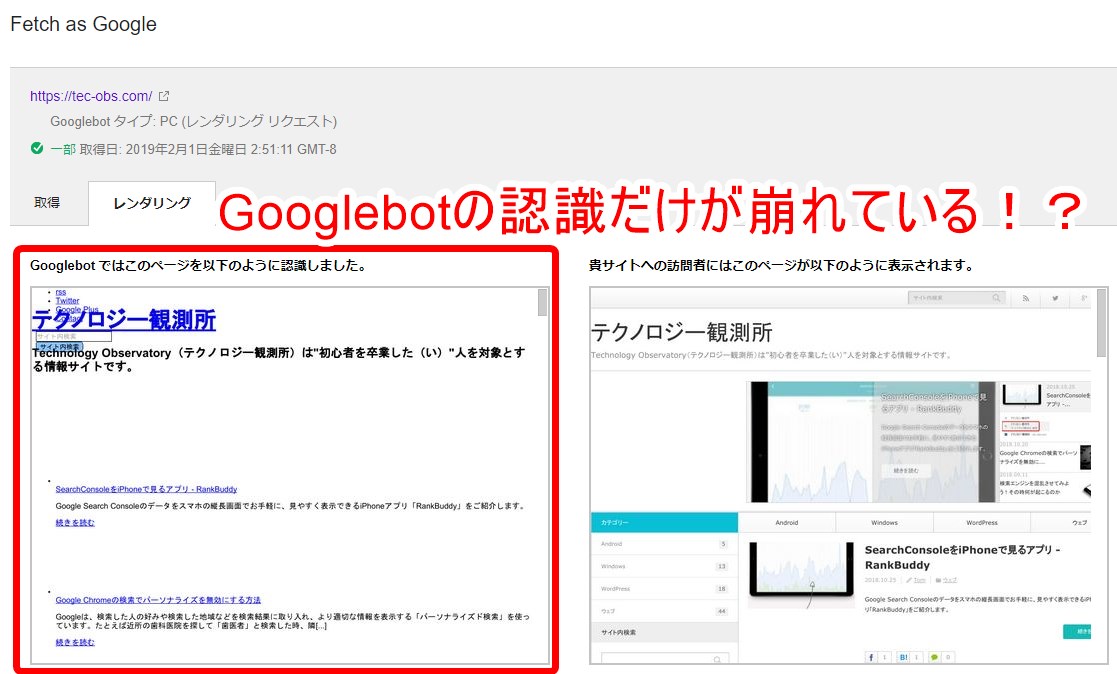
2つ並んでいるページキャプチャのうち左側がGooglebotに見えているもの、右側は実際にブラウザに表示した際に見えるもの(ユーザーに見えているもの)です。
ぶっちゃけてしまうと、自分が運用しているブログ「トムとロイド」「テクノロジー観測所(ここのことです)」「Photom」全部、この状態がずっと続いていました。
多くの場合、レンダリングがうまくいかない理由は特定のリソース(ほとんどの場合JavascriptかCSS)をGooglebot(クローラ)が取得できなかったせいです。
自分は多少なりサイトの仕組みは理解しているつもりでしたがJavascriptを読めるわけではない程度の知識レベルのため、どうしてGooglebotが特定のリソースを読めないのか、原因は長い間謎でした。
まぁクローラが読めなくても実際に表示することはできるし、ページの利用者に不都合はないし、何より冒頭で述べたようにすごく高い頻度でいろんなサイトで見かけるし、一般的にこんなものなのかなー程度の認識でした。
でも、ふっと閃いたんです。そういやウチのサイト、Robots.txtがやたら長かったっけって。
ひょっとして……?と思ったら案の定でした。
Robots.txtテスターで取得できなかったコンテンツをチェック
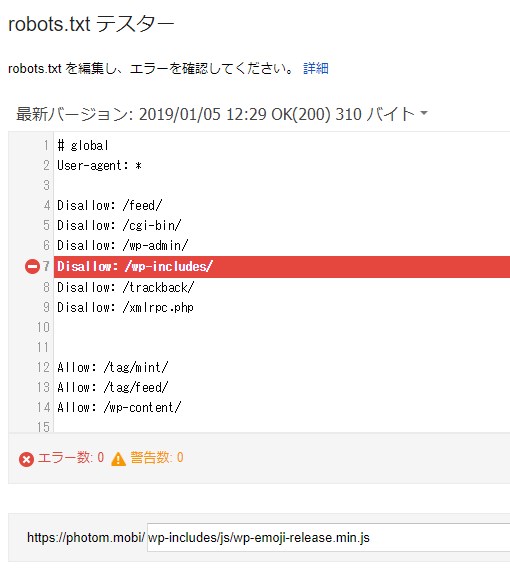
先程のFetch as Googleの結果画面を下にスクロールするとGooglebotが取得できなかったリソースのURLが並んでいます。
それを1つずつコピーして「Robots.txtテスター」でテストしてみました。
すると案の定、Robots.txtがブロックしているディレクトリに対象のリソースが格納されていました。
Robots.txtはクローラやスパイダーみたいなロボットに対して「このURLには来ていいよ」「このURLには来ちゃダメだよ」という命令を与えられるものです。強力だからしっかり確認して……って言ってたのに、自分自身が間違った設定をしていたとは…。
そもそも僕のブログのRobots.txtは「WordPress Robots」とかでググッて集めた情報で作りました。けっこういろんなサイトが、
- /wp-includes/
- /wp-plugin/
あたりを記述することを勧めていると思います。でもよくよく考えたらこの中にJSやCSSって入ってて当たり前な気がします。
とはいえ、それぞれのディレクトリごとにブロックする理由があるはずなので、僕みたいに他のウェブサイトの情報に頼る場合はそういうところまでしっかり確認してから判断したほうが良いです。
ちょっと前までGooglebot(クローラ)はJavascriptを読めませんでした。この頃に作成されたページでは、JSが格納されているディレクトリもRobots.txtでDisallow(拒否)するようにしていることも多かったと思います。
今すでにこれらのディレクトリをブロックしている場合、本当に解除して大丈夫かを確認するため、そのディレクトリの中に何が入っているかをFTP等を使って把握しておいてください。
とりあえず今回はシンプルに、
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://tec-obs.com/sitemap.xml
とだけ書いて送信してみました。
Robots.txtの編集作業は、FTP等を使ってサーバーのルートディレクトリからRobots.txtをダウンロードし、テキストエディタで行います。
Windowsなら「メモ帳」でできます。
大切なのは、いざ編集して新しい問題が起きた時、すばやく元の状態に戻せるようバックアップを取っておくことです。
中身を編集する前にRobots.txtファイルをコピーし、「Backup_]とかわかりやすい名前をつけておくと良いでしょう。
編集したらFTP等からサーバー側に上書き保存します。
Robots.txtテスターから更新リクエストを送信
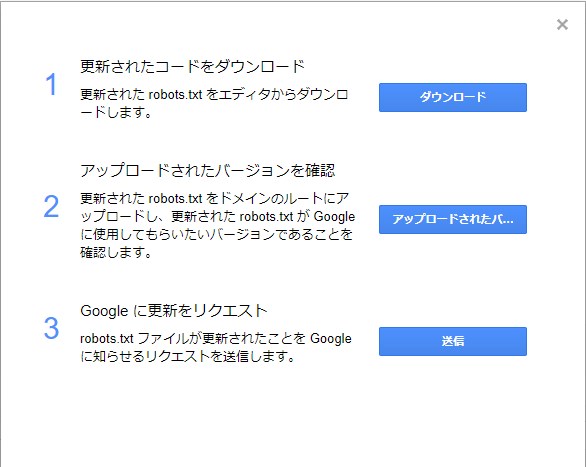
Robots.txtテスター画面の右の方にある「送信」ボタンを押すとこんなポップアップが出てきます。
上から3番目の「Google に更新をリクエスト」を押して、Robots.txtが更新されたことをGoogleに通知します。
数分待てば反映されるはずですので、Robots.txtテスター画面を更新してみましょう。更新されていたら、再度Fetch as Googleで取得してレンダリングを行い、結果を確認します。
この通り反映されていました。
なお、Robots.txtをシンプルにしてもGooglebotが取得できないリソースが残っていることがあります。
たとえば広告配信用のJSとか、WordPressの場合は親テーマのStyle.cssとか。(たぶん子テーマを使っているからじゃないかな?)
レンダリング結果はスクロールできるので、表示内容におかしなところがないか肉眼でしっかり確認してみましょう。サイトの作りによってリソースとなるJSやCSS等を置く場所はバラバラなので、よくよく確認を。
たとえばRobots.txtによってグローバルナビゲーションを構成するJSがブロックされていた場合など、Googlebotが認識できないためそこに紐付いたリンクが発見されず、クローリングされないという可能性もあります。
というわけで長い間気持ち悪かった問題が1つ片付いてほっとしました。
コメント