
Webサイトによっては、資料やホワイトペーパーなどを配布する目的でPDFファイルをサーバーに格納し、リンクしているケースがあります。
しかし様々な理由から、このPDFに直接訪問してほしくないため、PDFのインデックスを避けたいと考えていることがあります。
たとえば、PDFはHTMLではないので、直接訪問してしまうと他のページに遷移できず、離脱するしかないというのを嫌うようなケースとか。
そこでRobots.txtと正規表現を使って「Disallow: *.pdf$」みたいにして、PDFのクロールを禁止しているかと思います。
それでもPDFがインデックスに出現してしまう!という場合の原因と対処法について説明します。
PDFをDisallowしているのにインデックスされる原因はだいたいこれ
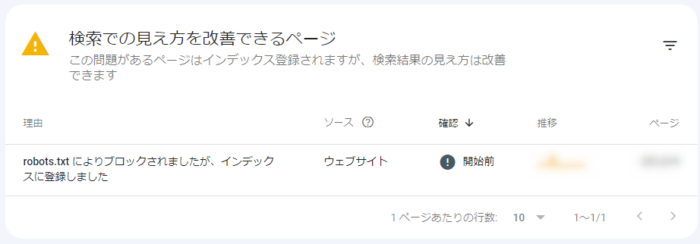
Search Consoleの「ページ」レポートの下部に、こんな項目が出現していることがあります。
「robots.txt によりブロックされましたが、インデックスに登録しました」という項目です。
この意味はそのまんま「Robots.txtでこのURLがブロックされているのは確認しました。でもクロール時にURLを見つけたから、インデックス登録しときますね」という、Googleの いらんお世話 粋なはからいです。
ここで考えることは「なぜ見つけられたのか」です。その答えはSearch Consoleのヘルプにあります。
このページはウェブサイトの robots.txt ファイルによりブロックされましたが、インデックスに登録されています。Google は常に robots.txt の内容に従いますが、他のユーザーがページにリンクしている場合、必ずしもインデックス登録が回避されるわけではありません。Google がページをリクエストおよびクロールすることはありませんが、ブロックされているページにリンクしているページの情報を使用して、インデックスに登録する可能性があります。また、robots.txt ルールが原因で、Google 検索結果に表示されるこのページのスニペットの内容が非常に限られたものとなる可能性があります。
Search Consoleヘルプ
GoogleはRobots.txtの記述に従ってURLをクロールはしないけど、そのページに向けた内部リンクを発見した場合「ページがある」こと自体はわかるので、とりあえずインデックスしておきますね。だって内部リンクがあるってことは、ユーザーに見てほしいんでしょ?
という感じでしょうか。
「ブロックされているページにリンクしているページの情報を使用して」なので、今回のケースでいえば、おそらく対象のPDFへの内部リンクを貼っているページには、このPDFのタイトルが書いてあることでしょう。それを参考にしているんじゃないかと推測します。
なので(実際にリンク先をクロールしたわけじゃないので)インデックスされた場合、タイトルのみでディスクリプションがない(「このページの説明はありません」等になる)ケースが発生するのではと思います。
余談ながら、こうした理由から、Robots.txtでDiasllowするファイルに向けた内部リンクは基本的に存在しないほうがいいです。多くの場合、Disallowした場所には .xml や .ini といったブラウザで開くことがないファイルが格納されることになると思うのでリンクしないとは思いますが、稀に「インデックスしたくない」という理由でDisallowを使っているケースがあります。
Robots.txtはあくまでも「クロール」を制御するだけなので、インデックスしたくない場合はNoindexを使い、クロールは「許可」します。クロールしてくれないとNoindexタグを見つけてもらえないので、クロールだけは許すかたちです。
更に補足として、 .js と .css はDisallowしてはいけません。クロールしてもらわないとGooglebotがページを正確に認識できなくなります。
PDFの場合、リンクしないとユーザーがアクセスできない。けどリンクするとクロール拒否してもクローラーに見つかっちゃう。というある種の矛盾が発生します。
これを解消するために、PDFに「Noindex」を付与することを推奨します。でもHTMLじゃないので meta name=”robots” content=”noindex” は使えません。ではどうするか?
インデックスして欲しくないPDFにはX-Robots-TagにNoindexをつける
注意
あくまでもNoindexするのは「インデックスしてほしくない(=検索結果に出現させたくない)PDF」だけです。
この作業をする前に、一度Search Consoleを確認してください。
そして「robots.txt によりブロックされましたが、インデックスに登録しました」に該当する項目(PDF)をチェックし、インデックスしたい(=検索結果に出現させてもいい)ものは、Noindexをつけない等個別に対処する必要があります。
最初にこのような切り分けをすることをおすすめします。
NoindexしたいPDFについては、下記のガイドラインに沿ってX-Robots-Tag HTTPヘッダーにNoindexを追加します。
Gogole検索セントラル – noindex を使用してコンテンツをインデックスから除外する
全てのPDFを一括でNoindexする場合
PDFの数が膨大で個別にNoindexするには手間がかかりすぎる場合、全てのPDFを一括でNoindexする方法もあります。
これには .htaccess を使います。リダイレクトなどを制御するファイルですが、サーバーソフトウェアによっては違うフォーマット(httpd.conf等)を使っていることがあります。
下記コードはあくまでも .htaccess 用なのでご注意ください。互換性とかはわかりません。(>人<;)
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex"
</FilesMatch>赤文字の部分に正規表現を使っており、「ファイル名(URL)の末尾が .pdf で終わるもの」という条件に対し、一致するファイルのX-Robots-Tagに一律でNoindexを追加します。
最後に – Noindexしたら、必ずクロールを「許可」する
インデックスさせたくない場合、「Noindex」を指定していることをクローラーに認識してもらうために、クロールは許可する必要があります。
X-Robots-TagにNoindexを追加した場合、Robots.txtからDisallowは削除してください。このことは検索セントラルにも書いてあります。
<meta> タグと HTTP ヘッダーを認識するには、Google がページをクロールできる必要があります。検索結果にページが引き続き表示される場合は、noindex ルールを追加した後にページがクロールされていない可能性があります。インターネット上でのページの重要性によっては、Googlebot がページに再度アクセスするのが数か月後になる場合があります。URL 検査ツールを使用すれば、Google にページの再クロールをリクエストできます。Google検索セントラル – noindex を使用してコンテンツをインデックスから除外する
注意しなければならないことは、「Disallow」と「Noindex」のどちらを先に付与したかです。
先にDisallowしていた場合、後からNoindexを付与しても(クロールされないので)検索エンジンに気づかれず、ずっとインデックスされ続けてしまいます。
こうした事故を回避するためにも、Noindexした場合はRobots.txtは「Allow」もしくは何も書かないようにして、クロールを許可する必要があります。
なお、100%絶対確実にインデックスから消したい場合は、PDFをサーバーから削除します。
配布方法を変えたり、あるいは中身が古くてもういらないケースなんかもあるかと思うので、確認してみることをおすすめします。

コメント