この記事は運営堂様のメールマガジン(毎日堂)で紹介されました!
前回はtitle、descriptionタグの重要性に着目するかたちで検索エンジンのロジックについて解説しました。
では逆に、ウェブマスターがページをクローラに選んでもらうためにやるべきことは何があるでしょうか。
基本中の基本となる仕組みについて、改めて考えてみました。
自分の記事を検索してもらうために必要な条件
簡単に理解するために、ゴール地点からルートを逆走するかたちで追ってみましょう。
↑
キーワードとコンテンツとの関連性が高いと判断される
↑
検索キーワードが使用される
↑
インデックス登録される
↑
クローリングされる
↑
コンテンツを作成する
おおまかにいってこのようなフローで記事が検索者に届けられます。
このフローの中でウェブマスターに制御できるのは以下の2つです。
- 検索エンジンに見てもらう(=クローリング)
- 検索エンジンに登録してもらう(=インデックス)
それぞれの制御方法をご紹介します。
クロールのしくみとページをクロールさせる方法

基本的に、コンテンツを公開したら放っておいても検索エンジンには登録されます。
しかし「いつ」登録されるのかはわかりません。登録作業には複数の段階があります。
まず最初に、検索エンジン側が「このサイトに新しいコンテンツが登場した」ことに気づく必要があります。このため検索エンジンは世界中に無数に存在するウェブサイト(URL)を自動的に訪問しまくっています。この作業を「クローリング」と呼びます。
ただ訪問するだけでなく、そのページにどんな情報が掲載されているのかも可能な限り把握しようとします。余談になりますがこの作業を「レンダリング」と呼びます。(厳密にはちょっと違いますが大目に見てくださいw)
クローリングした結果新しいコンテンツであることが認識されると、検索エンジンはそのURLを自身に登録します。この作業を「インデックス」と呼びます。
またも余談ですが、こうした作業をメインに行うことから、検索エンジンの訪問用ロボット(プログラム)のことを「クローラー」と呼ぶわけです。
もう1つ、何をもって「新しい」と判断するかですが、基本的にその根拠は「クロールしたものと同一のURLが既にインデックスされているか否か」で判断されると思っていいはず。
※既存のコンテンツを更新した場合の挙動については今回は省きます。
余談だらけになっちゃいましたが、要するに検索からの訪問を獲得するためには、まず検索エンジンへの登録(=インデックス)が必要。そしてインデックスされるには、検索エンジンが新規コンテンツを見つける作業(=クロール)が必要。そしてそのクロールが行われるタイミングは、先に書いた通りいつになるかわかりません。
早ければ数時間程度~遅ければ1ヶ月程度かかるという話も聞いたことがあります。
この間隔はクローラーが巡回に来る頻度でも変わります。日々大量のサイトを巡回する必要があることから、効率化のためクローラーは更新頻度の高いサイトには頻繁に訪問し、ほとんど更新されていないサイトは訪問する頻度を下げるといわれています。
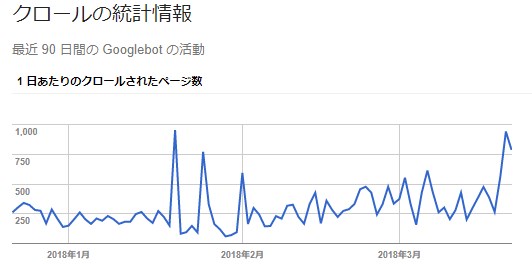
クロール頻度はSearchConsole(従来版)で見ることができますが、それよりもクローリングを制御するためにウェブサイトのほうからクローラーを呼ぶ方法について今回はお伝えします。
サーチエンジンクローラーを呼ぶ方法

検索エンジンをサイトに呼ぶ方法はいくつかあります。
まず最もメジャーなのはSearchConsoleを使ったもので、2種類あります。
Fetch as Googleは実は二度手間

1つ目はFetch as Google……といいたいところですがこれはクロールとレンダリングをテストする項目です。
ここからURLを送信しただけではインデックスのリクエストとはならないようです。

Fetch as Googleを使う場合、必ずクロール(またはレンダリング)後に「インデックス登録をリクエスト」ボタンを押す必要があるのでお忘れなく。
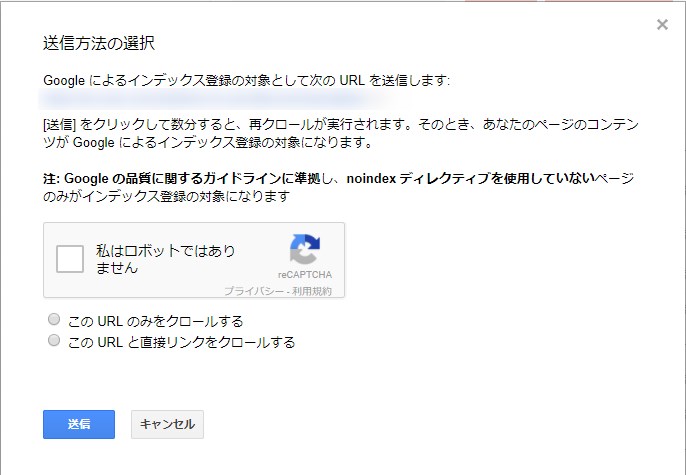
インデックス登録をリクエストする際はこのようなポップアップが表示されます。
noindexを指定していないか忘れずに確認を。している場合クロールされてもインデックスできません。
これとは別に、SearchConsole(従来版)にはコンテンツ(URL)を直接送信できる機能もあります。
ただ、従来版のSearchConsoleからこれを開くことはできないようで(もしできたらごめんなさい、項目見つけられず)、検索から辿り着く必要があるため少々面倒です。
ですので普通はFetch as Googleからインデックス登録をリクエストすると思いますw
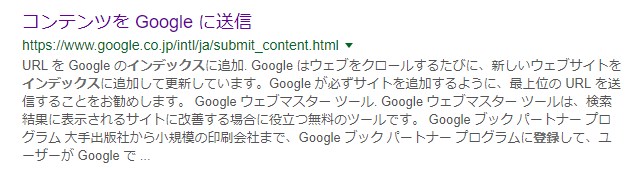
Googleで「インデックス登録をリクエスト」とかで検索すると、「コンテンツをGoogleに送信」というページがヒットします。
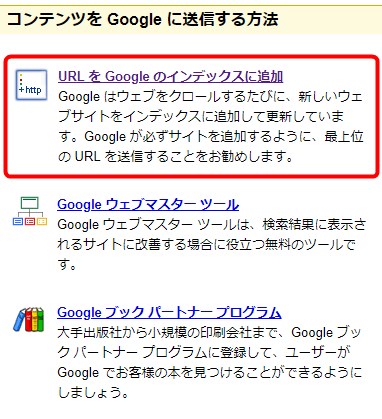
アクセスするとこういうページになるので、「URLをGoogleのインデックスに追加」を選びます。
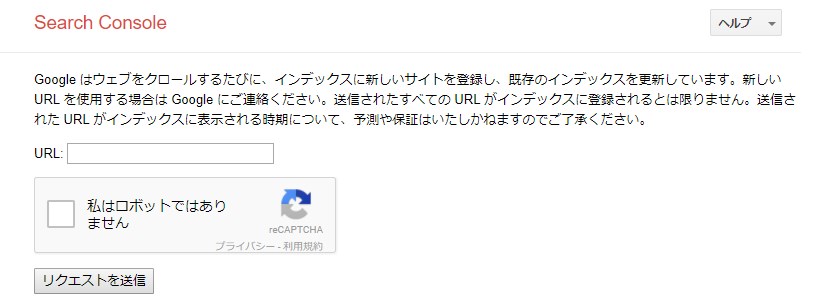
するとこういうページになるので、URLを登録します。
サイトマップを送信するのも有効
SearchConsoleからサイトマップをGoogleに送信することで、サイト内コンテンツの更新を知らせることもできます。複数のコンテンツを作った場合や一部コンテンツの場所(URL)を変更した場合にも有効です。というか構造を変更したら忘れずに提出するようにしましょう。
URLがウェブ上の住所だとするなら、サイトマップはその一覧を網羅した見取り図です。所有するドメインを1つの建物とするなら、サイトマップはその中のどこに何があるのかを示します。

サイトマップの送信はリニューアル版のSearchConsoleからも行えます。もちろん従来版でもできます。
また、手動で送信するだけでなく、定期的に自動でサイトマップを吐き出してGoogleに送信するWordPressプラグインなどもあります。
Google XML SitemapsとかAll in One SEO Packとかです。
どんな方法でもいいですが、サイトマップは基本的にXML形式のファイルに出力されます。ただ、大規模サイトになるとファイルが肥大化するため送信できなくなることがあります。Sitemaps.orgの記述によると、ファイル容量50MB以下、含めるURLは50,000以下である必要があります。それ以上のサイズ、URL数になる場合はサイトマップインデックスを使用します。サイトマップインデックスでは最大50,000個のサイトマップを含めることができ、またgzip形式の圧縮を利用できます。
さて今回も長くなってきましたが、クローラーを呼ぶ2つ目の方法をご紹介しますのでもうちょっとお付き合いください。いや、厳密には「呼ぶ」のではないのかな。こっちからURLを検索エンジンに送信します。
RSSフィードを送信する方法(PubSubHubbub)

こちらでご紹介した「PubSubHubbub(パブサブハブバブ)」を使います。今は「WebSub」と名前を改めたそうです。もうPuSHとは呼ばないのかな?
これはRSSリーダーに更新を通知するハブとして機能するものです。RSS/Atomフィードを公開している場合、購読者が増えてくるとその購読者が使用するリーダー全てから更新確認のリクエストを受け取ることになり、サーバーやネットワークの負荷が増大します。このためサーバー側で更新を確認するのをハブ1つに任せ、更新があった場合、このハブから各リーダーにURLを通知するという仕組みになっているそうです。
WordPressプラグインとしてもリリースされているので、使い方などはリンク先をご覧ください。
より詳細な情報は海外SEO情報ブログで見ることができますが、最近の情報だと、少なくともGoogle側ではサポートしているものの、きちんと機能しているかは確証が持てないそうです。
また2010年のGoogleのインデックスシステムの刷新(Caffeine)以降、インデックス速度は劇的に改善されているとのことで、必要性についても利用者個々の判断によるところが大きくなっているみたいです。
毎回記事を公開してからインデックスされるまで長い時間を要すると感じている場合は使うとかの判断が必要になるかな。
基本的に全部使っても問題ないかと思いますが、注意しなければならないのはそこではなく、「クロール」「インデックス」が適切に行えるようにサイトを健全な状態で維持することです。
Robots.txtでクローラーの訪問を拒んでいませんか?
検索してほしいページにnoindexタグを置いていませんか?
内部リンクが切れていてクローラーが辿れなくなっていませんか?
もしも何かしらの問題がある場合、こうした様々な角度からサイトの状態を確認してみてください。
また、無事検索結果に出現されるようになったとしても、キーワードボリュームや競合によって訪問が増えるかは左右されますので、その先も見据えてしっかり取り組んでいきましょう。


コメント