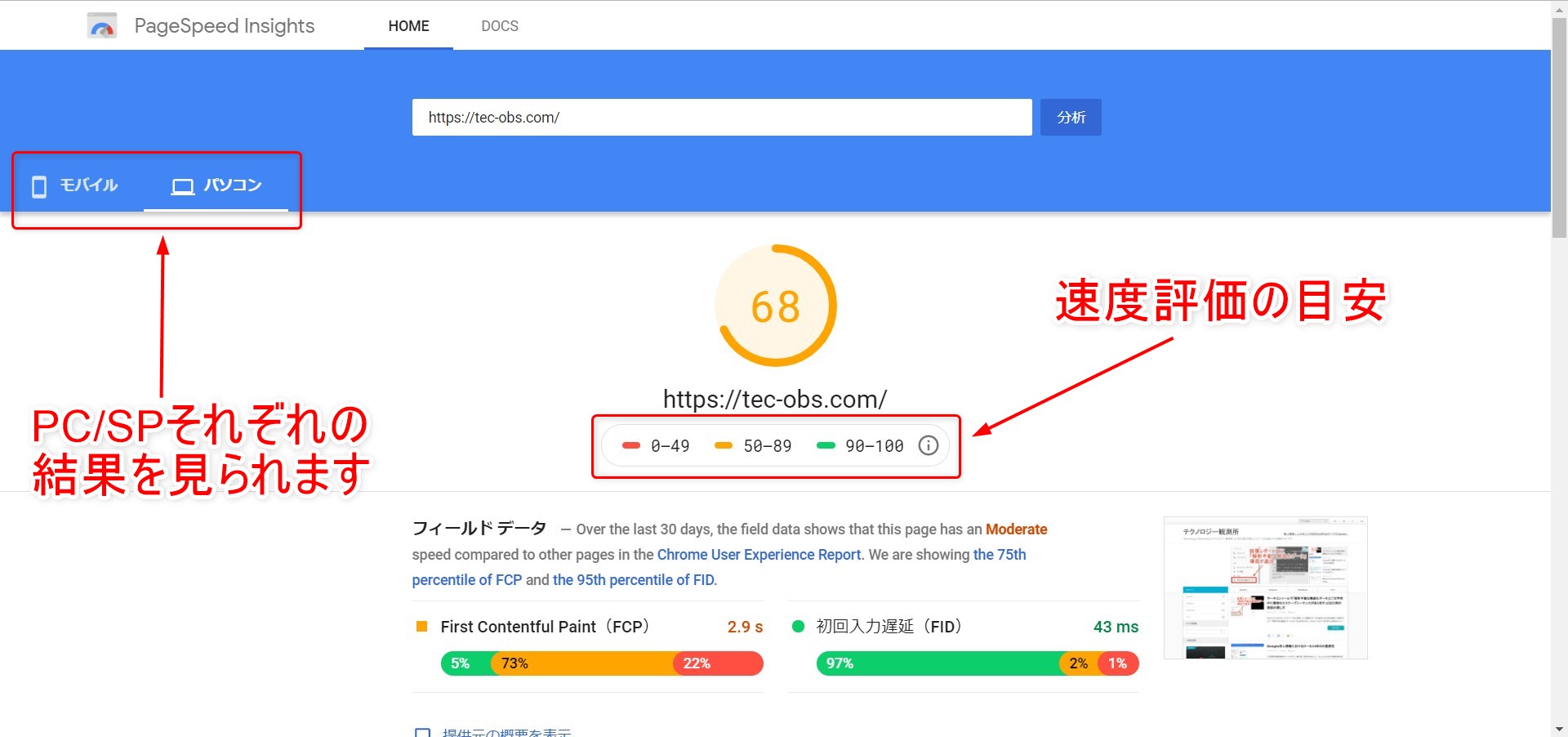
ゴールデンウィーク中にサーチコンソールにちょっと機能追加されましたよね。
具体的には、拡張レポート(リッチリザルト)の種類が増えたように思います。
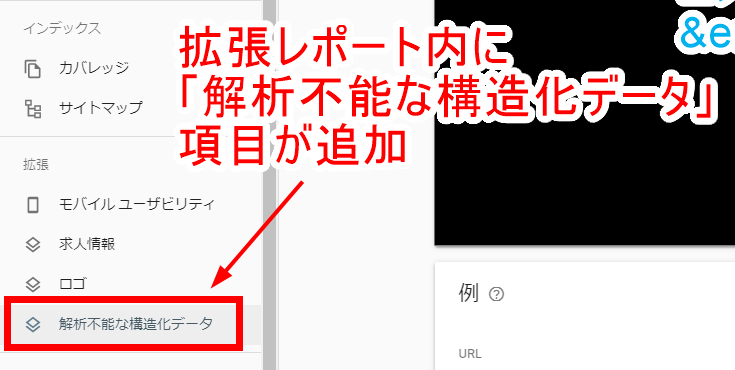
今までなかったものがいくつか登場していまして、その中でも「解析不能な構造化データ」というのが新手の記述ミス発見器として大変優秀なのではとの期待を抱いているため、その使い方を覚えておこうと思います。
ページ内に使用している構造化データの記述にミスがある場合にのみ出現する拡張レポート
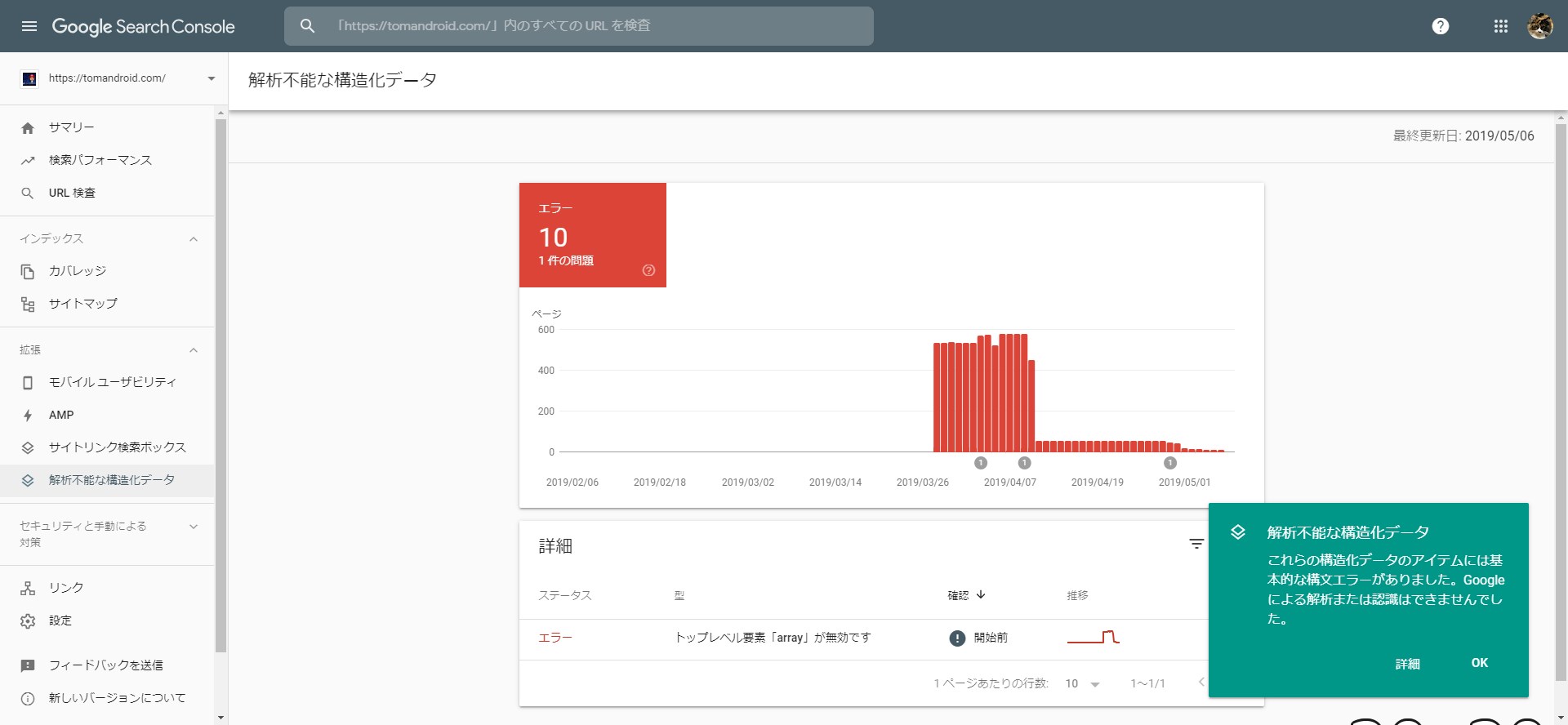
こちらはブログ「トムとロイド」のサチコです。
「モバイルユーザビリティ(=ページがモバイルフレンドリーだと出現)」と「AMP(=AMP版ページを持っていると出現)」は以前からあったのですが、「サイトリンク検索ボックス(=サイト内検索ボックスを検索結果に出すための構造化マークアップがある場合に出現)」と「解析不能な構造化データ(=ページ内に使用している構造化データの記述にミスがある場合に出現)」が増えていました。
つまり構造化データのマークアップにミスがあったってことか……orz
それは一旦おいといて、今回、この「解析不能な構造化データ」が出現している企業がやりがちな記述ミスの一例に遭遇したのでご紹介します。
求人関係のページで発生する「文字列中に無効なエスケープシーケンスがあります」というエラー
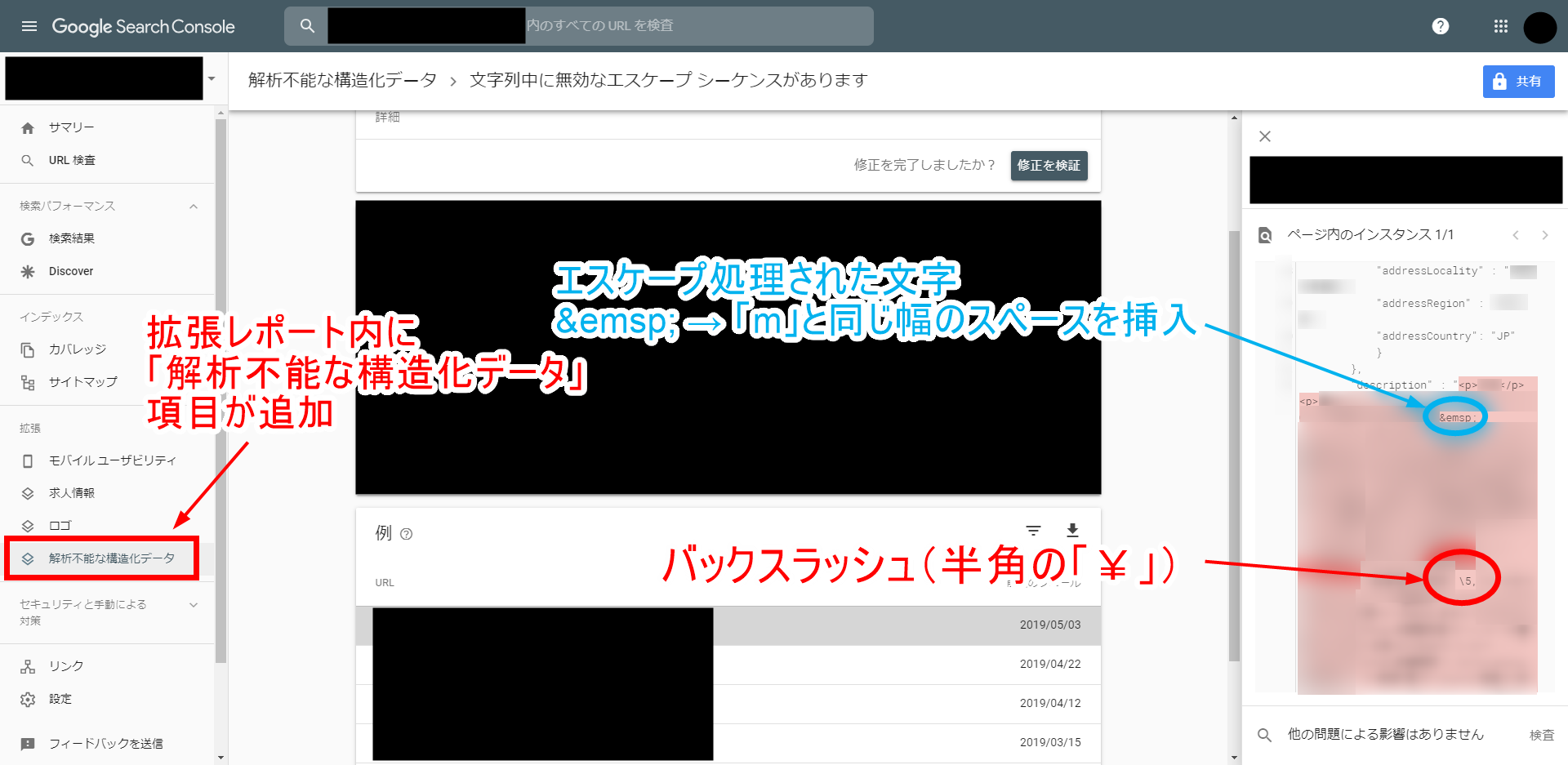
このキャプチャは仕事で担当しているクライアントのサイトなので、詳細は隠させていただいています。
サーチコンソールの「解析不能な構造化データ」の中に「文字列中に無効なエスケープシーケンスがあります」というエラーが表示されており、それをクリックした先の画面です。
ここではエラーに該当するページのURLが並んでいて、クリックすると右側にソースコード(インスタンス)が表示され、問題の箇所が薄い赤でハイライトされます。
今回発見したエラーは全て、JobPosting構造化マークアップ(要するにGoogle求人情報の構造化データ)に含まれる description の中で発生していました。
エスケープシーケンスとは
まず、このエラーがどんなものかを把握するためには「エスケープシーケンス」が何なのかを知る必要があります。

この記事で「エンコード、デコード」として紹介しているのですが、HTMLでタグなどを書き込む場合、半角の <> を使いますよね。
これってつまり、普通の文字として <> を使うことはできないってことです。なぜならブラウザがその部分を読み取った場合、 <> で挟まれたものは「何らかのHTMLタグだ」と認識して変換しようとするからです。
そこで、普通の文字として使えるように別の記号で <> を代替する仕組みがあり、この処理のことをエンコード(符号化)とかエスケープというんです。そしてそれを元に戻す「復号」という処理をデコードとか呼ぶわけです。
そしてエスケープ処理が必要な記号は <> 以外にも結構あります。それらを知りたい場合はお手数ですがググッてください。
もう一度この画像を使いますが、このキャプチャでは、   という部分がエスケープ処理されたコードです。
これを復号すると「半角小文字 m と同じ幅の空白(スペース)」になります。
ただ、結論からいうとこれは今回のエラーの原因ではありませんでした。なぜならエラーと診断されていない、正常なページにも使われていたからです。
そこで、先程のサーチコンソールでハイライトされた文字列の中で他に該当する「エスケープ処理されてそうな箇所」を探してみたところ、見つかったのが「¥」マークでした。
ご存知、日本円の通貨記号ですが、これを半角で記述すると \ (バックスラッシュ)に変換されることもあります。
他に候補がないためここが原因だと思うわけですが、たぶんJobPosting構造化マークアップのdescriptionに「¥」が含まれている場合、無効なエスケープシーケンスと認識されるのではないかと思われます。
場所がJobPostingの構造化データだったため、求人関係のサイトで発生しやすいエラーだと思った次第です。
時給表記に¥マーク使ってませんか?
今回このエラーが発生していたサイトは幸いにも定型文ではなく、補足として表記が必要なページのみこの記号が使用されていたため、エラーの件数は極わずかでした。
ですが時給、月給の表記に標準で使っている場合、ものすごい数のエラー数になる可能性もあるかもしれません。
もしまだサーチコンソールを見ていない場合、確認したほうがいいかもしれませんよ。
コメント